ตามนิยาม (ในวิกิพีเดีย) เค้าบอกไว้ว่า
Serilizationคือกระบวนการแปลงวัตถุให้กลายเป็นสายข้อมูลในรูปแบบบิตทำให้สามารถเก็บรักษาวัตถุดังกล่าวไว้บนสื่อเก็บข้อมูล (เช่น HDD)หรือจะเอาไปส่งผ่าน Network ก็ได้
Deserilization คือกระบวนการย้อนกลับของ Serialization คือการแปลงจากสายข้อมูลในรูปแบบบิตให้กลับมาเป็นวัตถุของเรานั่นเอง
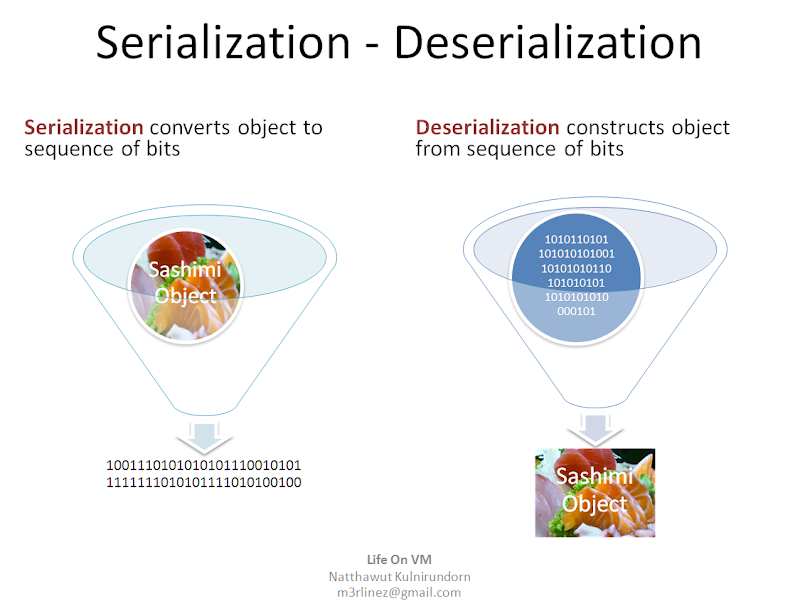
จากรูป วัตถุ "ปลาดิบ" จะถูกแปลงเป็นข้อมูลในรูปแบบ Binaryเพื่อเก็บไว้บนดิสค์ครับและหากต้องการนำมาใช้ใหม่ก็แค่โหลดข้อมูลขึ้นมาทำการ Deserialzation
จริงๆแล้วขั้นตอนการเก็บรักษา "สถานะ" ของวัตถุตามที่เห็นในรูปมันก็สามารถทำมือได้เช่นกัน โดยอาจจะเขียนข้อมูลต่างๆใส่ Text Fileแล้วเขียนลอจิกที่ทำหน้าที่โหลดข้อมูลดังกล่าวขึ้นมาเองแต่ตามความเข้าใจของผมวิธีการนี้ก็เป็นวิธีการหนึ่งในการเก็บรักษาสภาพของวัตถุที่สะดวกดีครับเขียนเพิ่มนิดหน่อยก็ทำ Serialization ได้เลย
วิธีการทำใน C# มีขั้นตอนดังต่อไปนี้ ยกตัวอย่างจากคลาสที่เขียนในวันนี้
- เพิ่ม Attribute Serializable เข้าไปที่หัว Class ก่อน
- ให้ Class implements ISerializable ต้องเขียน method GetObjectData เพิ่ม
- ทำ Deserialization Constructor ที่มีรูปแบบตามที่กำหนด
- เพิ่มลอจิกส่วนที่เป็นการทำ Serialize และ Deserialize
ส่วนของ ToBinaryFile และ FromBinaryFile เป็นส่วนของข้อ 4 นะครับ
เวลาจะทำ Serialize ก็เรียก ToBinaryFile("filename.osl") และเวลาจะ Deserialize ก็เรียก Word.FromBinaryFile("filename.osl")
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Net;
using System.Runtime.Serialization;
using System.Runtime.Serialization.Formatters.Binary;
using System.IO;
namespace WordParser
{
[Serializable()]
class Word : ISerializable
{
public string Value { get; set; }
public string Description { get; set; }
public int Popularity { get; set; }
public Word()
{
}
public Word(SerializationInfo info, StreamingContext context)
{
Value = (string)info.GetValue("Value", typeof(string));
Popularity = (int)info.GetValue("Popularity", typeof(int));
Description = (string)info.GetValue("Description", typeof(string));
}
#region ISerializable Members
public void GetObjectData(SerializationInfo info, StreamingContext context)
{
info.AddValue("Value", Value);
info.AddValue("Popularity", Popularity);
info.AddValue("Description", Description);
}
#endregion
public static Word FromBinaryFile(string file)
{
using (Stream stream = File.Open(file, FileMode.Open))
{
BinaryFormatter bformatter = new BinaryFormatter();
Word ret = (Word)bformatter.Deserialize(stream);
return ret;
}
}
public void ToBinaryFile(string file)
{
using (Stream stream = File.Open(file, FileMode.Create))
{
BinaryFormatter bformatter = new BinaryFormatter();
bformatter.Serialize(stream, this);
}
}
}
}
Credit: DevStock













